
크게 부각되진 않았지만 얼마 전 네이트와 네이버에서 각각 ‘시맨틱’ 및 ‘시맨틱 웹’ 검색 서비스를 내놓은 적이 있었다.
네이트는 연초부터 베타 테스트를 하던 시맨틱 검색 기능을 오픈했다. 이 기법은 구문이나 문장 분석에서 중요 주제어를 추출하고, 이에 대한 값을 찾는 자연어 처리기술을 도입했다.
따라서 블로그, 게시판과 같은 구조화되지 않은 텍스트를 대상으로 주제 분류와 예상 답변을 제시하는 방식으로 그 뼈대는 일반적인 텍스트 기반 정보 검색(IR) 기법을 기반으로 하고 있다. 주제어 제시 방식이 마치 의미 기반 정보를 찾아 주는 것으로 보여 시맨틱이란 용어를 쓰는 듯 하다.
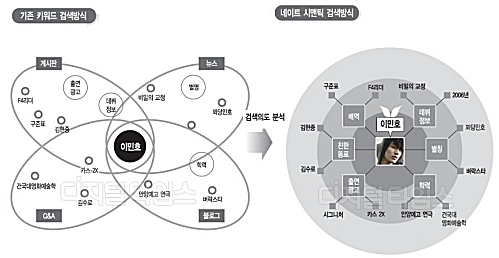
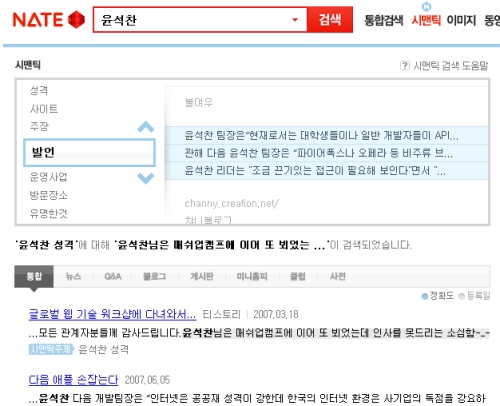
그런데, SK컴즈의 보도 자료를 보면 ‘시맨틱 웹’이라는 생뚱 맞는 내용을 등장시켜 혼란을 주고 있다.
시맨틱 검색은 1998년 시맨틱 웹이 주창되면서부터 차세대 검색서비스로 주목받으며 전세계적으로 연구개발이 진행되고 있는 분야이다. MS의 Bing이나 구글의 스퀘어드(Squared) 검색도 시맨틱검색의 일종이다. 국내에서는 솔트룩스나 시맨틱스가 시맨틱 검색을 개발하고 있다. 이같은 방식은 하키아(Hakia)와 파워셋(Powerset) 등 해외 시맨틱 검색 업체들이 개발했으나 실험실 단계에서 오픈해 아직 포털에 적용되지는 못했다.
정보 검색에 대한 두 가지 접근에서 보다시피 네이트가 이용한 (시맨틱) 기술은 전산학에서 꽤 오래된 분야로서 텍스트 분석, 자연어 처리, 기계 학습과 같은 분야는 인공 지능 분야에서 시맨틱 기술을 말하는 것이다.
하지만, 시맨틱 웹은 이와 완전히 다른 접근이다. 시맨틱 웹은 웹을 데이터 단위로 구조화 시켜상호 관계성을 파악하려는 시도 즉, 웹을 데이터베이스화 혹은 지식 기반으로 만들고 이를 기반으로 추론을 목표로 한다. (물론 웹을 이렇게 만드는 것은 완벽히 실패했다.)
다행히 위키피디아를 통해 웹에서 구조화된 데이터가 가능 하다는 것을 보여준 이후, 이를 RDF 방식으로 변환 시킨 DBPedia라는 프로젝트로 인해 크게 바뀌었다. LinkedData라고 불리는 이름으로 RDF 기반으로 데이터 웹을 구조화 시키거나 RDFa나 마이크로포맷 같은 방식으로 HTML 의미 마크업을 시도하고 있는 것이다.
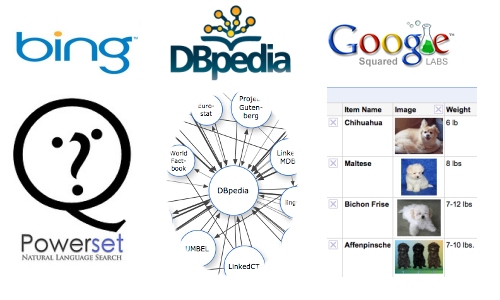
구글의 스퀘어드나 MS가 인수해 Bing에 추가한 파워셋의 경우, 위키피디아의 구조화된 DB를 기반으로 한다. 시맨틱 웹 검색의 시초라할 수 있는 하키아 역시 LinkedData를 기반으로 하고 있고 일부 NLP 기술을 반반씩 섞고 있는 상태이다.
따라서 이 두 가지를 어느 정도 분리해서 이야기해야 혼란을 피할 수 있다. 네이버의 이준호 박사님이 지난번 인터뷰에서 시맨틱 웹 검색 기술에 대해 의아하게 여긴것도 이 때문이다.
시맨틱 검색 계획은 어떤가? “시맨틱 웹이라는 건 연구자마다 정의가 다양해서..그래서 시맨틱 웹이라고 할 때 그것이 정확히 뭘 의미하는지 사실 잘 모르겠다. 의미 연관 검색그런 방식의 이 가장 시맨틱 검색에 근접한 정의일 텐데 그런 의미 기반 검색은 60년대부터 있었다. 이후 풀 텍스트 검색으로 많이 전환 됐다. 현재 알려진 것 중 마이크로소프트의 ’빙‘이 시맨틱 방식일 건데 우리도 검토하고 있기는 하다.온톨로지 검색 차원에서 노력하고 있다.”
네이버에서 온톨로지 검색 차원에서 노력한 결과로 나온 것이 영화 시맨틱 검색이다. 영화 콘텐츠 DB의 관계성을 RDF로 추출(Exporting)한 후 URI를 기반으로 그래프를 따라 의미를 쫓아가는 방식이다.
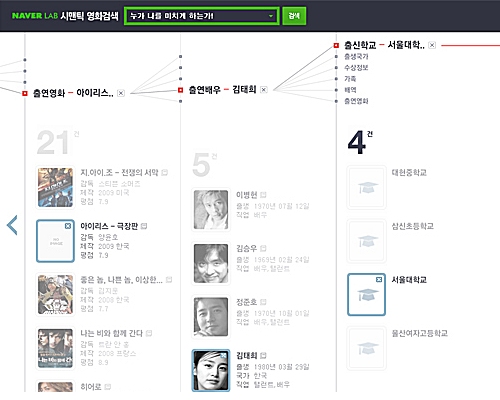
이와 같은 시맨틱 웹 검색 방식은 구조화된 지식을 담고 있는 그릇이 필수적이다. 포털의 경우, 영화나 음악 같은 DB를 RDF로 관계를 정하고 이를 URI 기반으로 사용자 콘텐츠와 유기적으로 엮음으로서 좀 더 의미적인 시맨틱 웹 검색이 가능할 것이다.
아직까지 기존 텍스트 기반 웹 검색에서 출발한 ‘시맨틱 검색’과 웹을 DB로 보고 이를 의미 기반으로 연결할 ‘시맨틱 웹 검색’ 어느쪽이 성공할지는 알 수 없다.
하지만, 개인적으로는 후자가 좀 더 웹에 어울리는 것이 아닌가 싶다.
그러기 위해서는 사람들의 집단 지성에 의한 콘텐츠 저작 방식과 협업을 통한 지식 기반 구축이 가능하다는 것을 전제로 해야 한다. 위키피디아가 아직까지 어려운 이유가 저작 방식에 있고 사용자들은 의미를 달리해서 정보를 저작하는 데 아직까지도 익숙치 않다.
2006년에 의미적 글쓰기(Semantic Writing)이라는 글에서 저작 기능에서 의미적 데이터를 구분해서 저장하는 도구의 중요성에 대한 이야기를 했었다. 지금의 오픈 API와 같은 데이터 저장소와 RDFa와 마이크로 포맷(혹은 HTML5의 Microdata)과 같은 시맨틱 마크업을 통해 가능하지 않을까 싶다.
웹의 발전이 사람의 손에 의한 것이었던 것처럼 시맨틱 웹 검색의 가능성 역시 사람에게 달려 있다.