
1부 1장의 내용을 보면 루씬에 대한 소개, 일반적인 검색 애플리케이션의 구조, 기본적인 색인 API, 기본적인 검색 API에 대해서 설명하고 있다. 이 글을 리뷰하는것은 필자의 주관적인 생각도 들어갈수 있으며, 모든 저작권은 루씬 저자와 옮긴이에게 있으며, 자세한 내용을 알고 싶다면 책을 사 보는것을 추천한다.
여기서 루씬이라는 것은 어떤 애플리케이션이건 간에 손쉽게 검색 기능을 추가 할수 있게 도와주는 강력한 자바 검색 라이브러리를 말한다. 더군다나 루씬의 직관적이고 간결한 API덕분에 단 몇개의 클래스 만을 사용해도 기본적인 색인과 검색 기능을 충분히 활용할수 있다. 다시말해 루씬은 고성능 정보 검색 라이브러리 이다. 루씬을 사용하면 애플리케이션에 정보 검색 기능을 추가 할수 있으며, 루씬의 API는 최소한의 노력으로 풀텍스트 색인과 검색 기능을 사용할수 있게 충분히 간결하면서도 매우 강력하다. 루씬의 핵심 JAR 파일 이외에 추가 기능을 담당하는 여러개의 확장 JAR파일이 있다. 확장 기능이지만 루씬을 사용할 때 거의 모든 애플리케이션에서 필요로 하는 중요한 JAR 파일도 있으며 예를 들어 맞춤법 검사 기능이나 결과 하이라이팅 등의 기능이 있다.
1.2 루씬의 역사
루씬은 최초에 더그 커팅이 개발했으며, 처음에는 소스포지 사이트의 루씬 프로젝트 페이지에서 내려 받을수 있었다. 그러다가 2001년 8월에 아파치 재단의 자카르타 프로젝트의 일원으로 아파치 재단에 합류하였으며, 2005년에는 아파치 재단의 최상위 프로젝트가 됐다.
http://lucene.apache.org에서 관련 정보를 찾아 볼수 있으며, 현재 4.5버전까지 릴리즈 된 상태 이다.
1.3 루씬과 검색 애플리케이션의 구조
지금부터 소개할 검색 애플리케이션은 색인 절차를 구현하고 있다. 즉, 원본 파일을 가져와 루씬 문서의 형태로 변환하고, 마지막으로 변환된 텍스트를 색인에 추가한다. 이렇게 색인을 구성하고 나면 애플리케이션의 사용자 인터페이스를 통해 사용자가 찾고자 하는 검색어를 루씬 질의로 변환하고 색인을 대상으로 준비한 루씬의 질의를 실행 결과를 받아오고 최종적으로 화면에 결과를 출력한다.
사용자-> 검색화면 인터페이스-> 검색질의생성-> 질의실행->색인에서 검색-> 질의결과 출력
검색대상->검색대상텍스트 확보-> 루씬문서생성->문서텍스트 분석->색인에 문서추가->색인
1.3.1 색인 과정 구성요소
– 검색 대상 텍스트 확보
이단계에서는 흔히 말하는 문서수집기(크롤러)를 사용해 색인할 대상의문서를 모은다. 특히 문서에 접근할 때 보안 정보가 필요하다면 대상에 따라 접근 권한을 확보해야 하기 때문에 좀더 복잡해 진다. 게다가 검색할 때 인증되지 않은 사용자가 아무 문서나 볼수 없게 하려면 접근 권한이나 접근 제어 목록 등의 장치가 있는 경우 권한 정보를 색인에 함께 보관해야 한다. 검색대상확보와 관린이 깊은 기능은 기본적으로 포함하지 않는다 따라서 상황에 따라 추가적으로 연동할수 있는 기능들을 알아 두면 좋다.
간단하게 이름만 적으면, 솔라, 너치, 그럽, 헤리트릭스, 드로이드, 어퍼쳐, 구글 엔터프라이즈커넥터 메니저 정도가 있다.
-루씬 문서 생성
검색할 대상 문서의 원본을 확보하고 나면 해당 원본을 루씬에서 사용하는 개별 단위, 즉 문서로 변환해야 한다. 루씬 문서는 이름이 붙은 여러 개의 필드로 구성되며, 예를 들어 책에 대한 정보를 검색 한다면 각 문서에 제목, 본문, 요약, 저자, 링크 등의 필드가 들어가야 한다. 원본 파일의 내용을 분석해 원하는 여러 종류의 필드로 구분하고 문서를 구성해야 한다. 예를 들어 이메일 메시지의 내용을 루씬문서로 생성하는 경우 각 메시지를 루씬 문서 하나로 변환하고 PDF 파일이나 웹페이지는 개별 파일이나 페이지를 문서로 생성하면 무리가 없다. 하지만 간혹 문서로 명확하게 구분 할 수 없는 경우도 있는데 예를 들어 이메일 메시지에 포함된 첨부파일은 어떻게 처리할까? 모든 첨부파일에서 텍스트를 추출한 다음 본문으로 간주해야 할지, 아니면 각 첨부파일을 개별 루씬문서로 만들고 대신 포함돼 있던 이메일 메시지에 대한 링크를 담게 구성해야 할수 도 있다.
상황에 따라 원본 문서에는 없는 정보를 추가해 필드를 생성하면 도움이 되는 경우도 있다. 예를 들어 본문 텍스트 필드에 들어있는 텍스트를 대상으로 의미 분석과정을 거쳐, 인명, 지명, 날짜 , 시각, 주소 등의 정보를 추출해 별도의 필드에 보관할수 있다. 아니면 데이터베이스처럼 별도의 공간에 저장된 정보를 가리키는 링크나 ID등을 필드로 추가하면 루씬 내부에 하나의 문서로 연결해 보관 할수 있다.
-문서 텍스트 분석
어떤 검색엔진이든 텍스트를 직접 색인하진 않는다. 대신 텍스트를 토큰이라고 부르는 단위로 잘라낸다. 이런 토큰 추출 작업이 텍스트 분석과정에서 가장 중요한 작업중 하나다. 일반적으로 토큰은 사람이 눈으로 보는 단어에 해당하며, 분석 과정에 구현된 내용에 따라 필드에 담긴 텍스트를 토큰으로 어떻게 추출 할 것인지를 결정하게 된다.
– 색인에 문서 추가
색인과정을 모두 거치고 나면 문서가 색인에 추가된다. 루씬에는 이미 문서를 색인에 추가하는데 필요한 모든 기능이 준비돼 있으며, 매우 간단한 API를 통해 처리할 수 있다.
1.3.2 검색 과정 구성요소
검색은 색인에 들어있는 토큰을 기준으로 해당하는 토큰이 포함된 문서를 찾아내는 과정을 말한다. 검색의 품질은 흔히 정확도와 재현율로 표현하기도 한다. 재현율은 검색 시스템에서 관련된 문서를 얼마나 빼먹지 않고 찾아주는지를 뜻하고, 정확도는 검색 시스템에서 사용자가 입력한 검색어와 관련 없는 문서를 얼마나 정확하게 제거하는지를 뜻한다.
– 검색 사용자 인터페이스
사용자 인터페이스는 말 그대로 사용자가 웹 브라우저나 데스크탑 애플리케이션, 휴대용 기기 등에서 직접 보면서 검색 애플리케이션을 사용하는 화면이다. 사용자 인터페이스는 결과적으로 검색 애플리케이션에서 가장 중요한 부분이라고 할수 있다. 인터페이스는 최대한 간결하게 유지하는 편이 좋다. 첫 페이지부터 온갖 고급 검색 설정 등을 보여줄 필요는 없다. 검색 버튼을 누르면 검색어를 입력할수 있는 화면이 나타나는 대신 언제든지 보고 사용할수 있는 일관적인 검색어 입력화면을 배치하자. 하지만 루씬에는 기본 검색 사용자 인터페이스가 들어있지 않다. 따라서 사용자 인터페이슬ㄹ 만드는 일은 전적으로 애플리케이션 개발자의 책임이다.
– 검색 질의 생성
사용자가 검색 애플리케이션을 사용한다는 말은 검색어를 입력한다는 것과 같은 의미며, 일반적으로 html폼이나 ajax 요청의 형태로 브라우저에서 서버에 검색어를 전달한다. 그러면 서버는 전달받은 검색어를 검색엔진에서 인식하는 query 객체로 변환해야 하며, 이런 과정을 질의 생성 절차라 부른다.
– 질의로 검색
실제 색인을 뒤져 검색 질의에 생선한 query 객체에 해당하는 결과를 적당한 정렬 순서에 맞게 받아올 차례다. 정보를 검색 하는 분야에는 다음과 같이 크게 세 종류의 이론 적인 검색 모델이 있다.
1. 순수 블리언 모델: 질의된 질의에 문서가 해당하는지 아니면 해당하지 않는지를 판단하며 별도의 점수 계산 부분은 없다.
2. 벡터공간 모델: 질의와 문서 모두 고차원공간의 벡터로 표현한다. 따라서 벡터간의 거리를 계산하면 문서와 질의 사이의 연관도나 유사도를 산출할수 있다.
3. 확률 모델 : 확률적인 방법을 통해 개별 문서가 질의와 일치하는 확률을 계산한다.
– 결과 출력
질의에 해당하는 결과 문서를 원하는 순서에 따라 정렬된 상태로 확보하고 나면 이제 사용자가 짖관적으로 알아보기 좋게 화면에 출력한다.
1.3.3 검색 애플리케이션의 나머지 요소
– 관리 인터페이스
검색엔진은 복잡한 내부 구조를 갖고 있으며, 설정할수 있는 항목이 매우 많다. 문서 수집기를 사용해 검색 대상을 수집한다면 관리 인터페이스에서 문서 수집을 시작할 최초 URL을 지정하거나 문서 수집기가 돌아다녀야 할 대상 사이트를 판단하는 규칙등을 지정할 수 있어야 하고, 수집할 문서의 종류나 각 페이지를 이동하는 속도도 지정할 필요가 있다. 데스크탑 검색 같은 개인 사용자용 검색 애플리케이션에 관린 인터페이스가 필수적인 것은 아니지만, 기업용 검색 애플리케이션은 관리 인터페이스가 필수적이며, 매우 복잡한 설정 기능을 갖고 있는 경우도 많다.
– 분석 인터페이스
일반적으로 웹 기반으로 구성하는 경우가 많고 보고서 작성 엔진과 함께 별도의 서버에 설치하는 경우가 많다. 분석은 매우 중요한 정보를 제공한다. 분석 인터페이스에서 제공하는 정보를 보면 검색 애플리케이션의 사용자에 대한 정보를 얻을수 있으며, 검색 로그에 기록된 검색 질의 패턴을 잘 살펴보면 사용자가 검색 애플리케이션에서 어떤 결과를 원하는지 파악할 수 있다.
루씬을 사용한다면 다음과 같은 분석 정보를 제공 할수 있다.
1. 실행된 질의 종류별 빈도수
2. 연관도가 낮은 결과를 뽑아 낸 질의
3. 사용자가 결과에서 아무 항목도 클릭하지 않은 질의
4. 연관도 대신 별도의 필드 기준으로 정렬하는 빈도수
5. 루씬에서 검색하는데 걸린 시간 내역 분석
1.4.1 색인 생성
Indexer라는 간단한 색인 프로그램을 작성한다. Indexer 프로그램은 지정한 디렉토리 안에 들어 있는 모든 파일의 내용을 색인하며, 색인된 내용은 searcher프로그램에서 직접 사용한다.
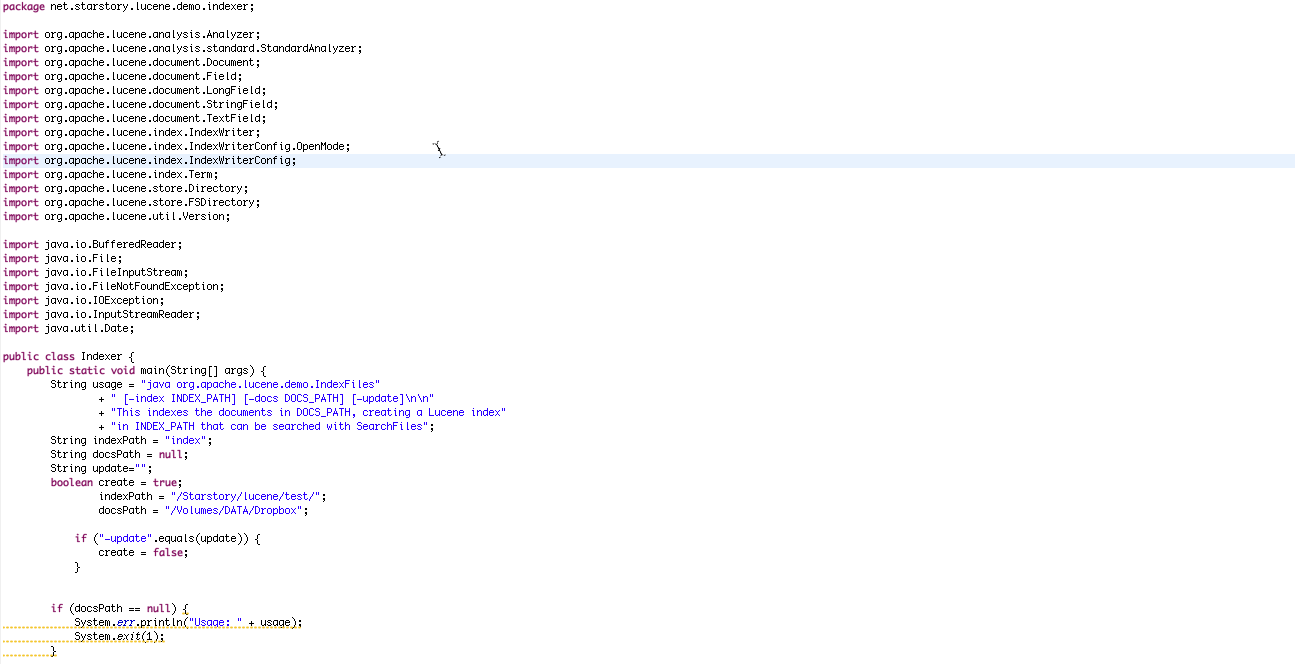


1.4.2 색인의 내용 검색
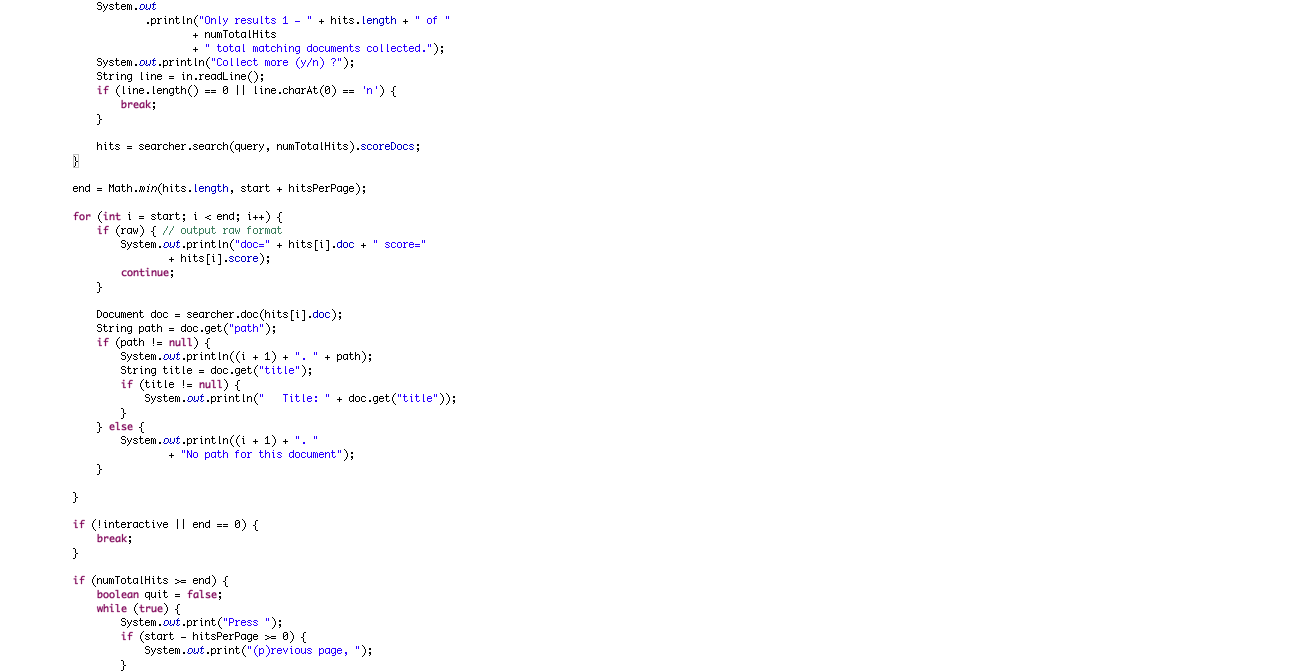
루씬에서 검색 기능은 색인 기능 만큼이나 빠르고 간단하다. 생성한 색인의 내용을 검색하는 커맨드 라인 실행 프로그램인 Searcher 프고그램을 살펴 보자
– 검색 기능을 구현한 Searcher 프로그램
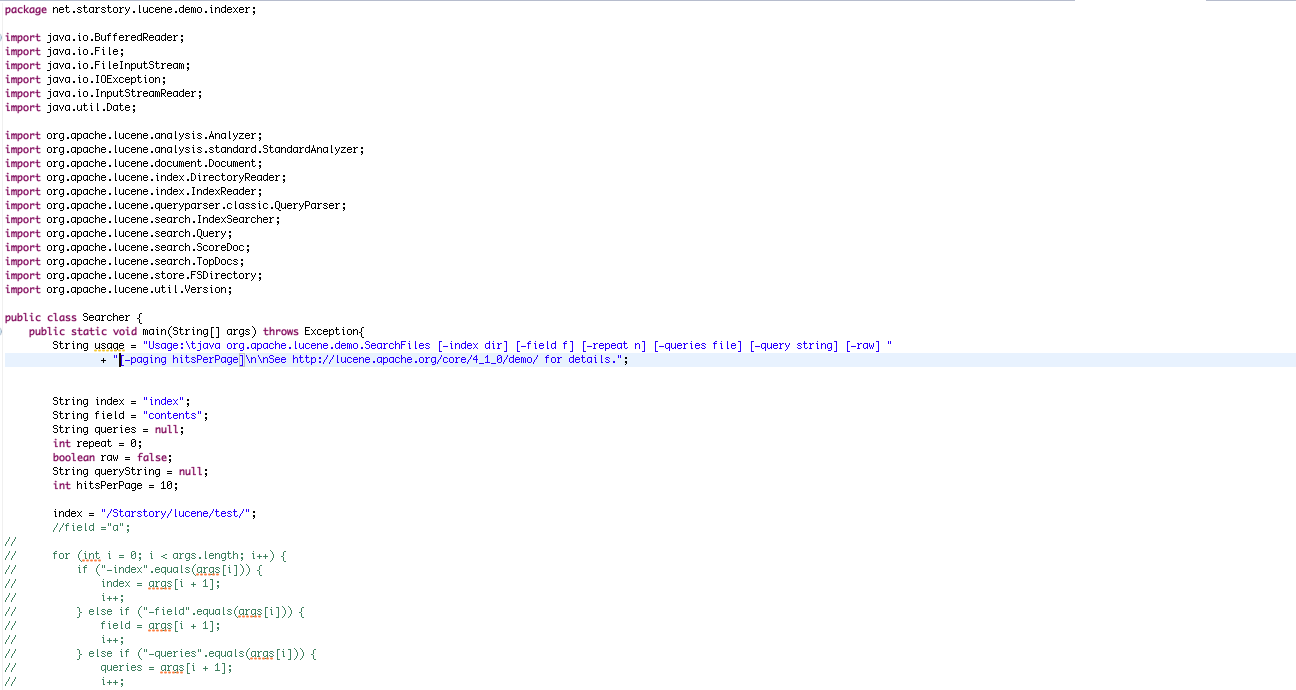
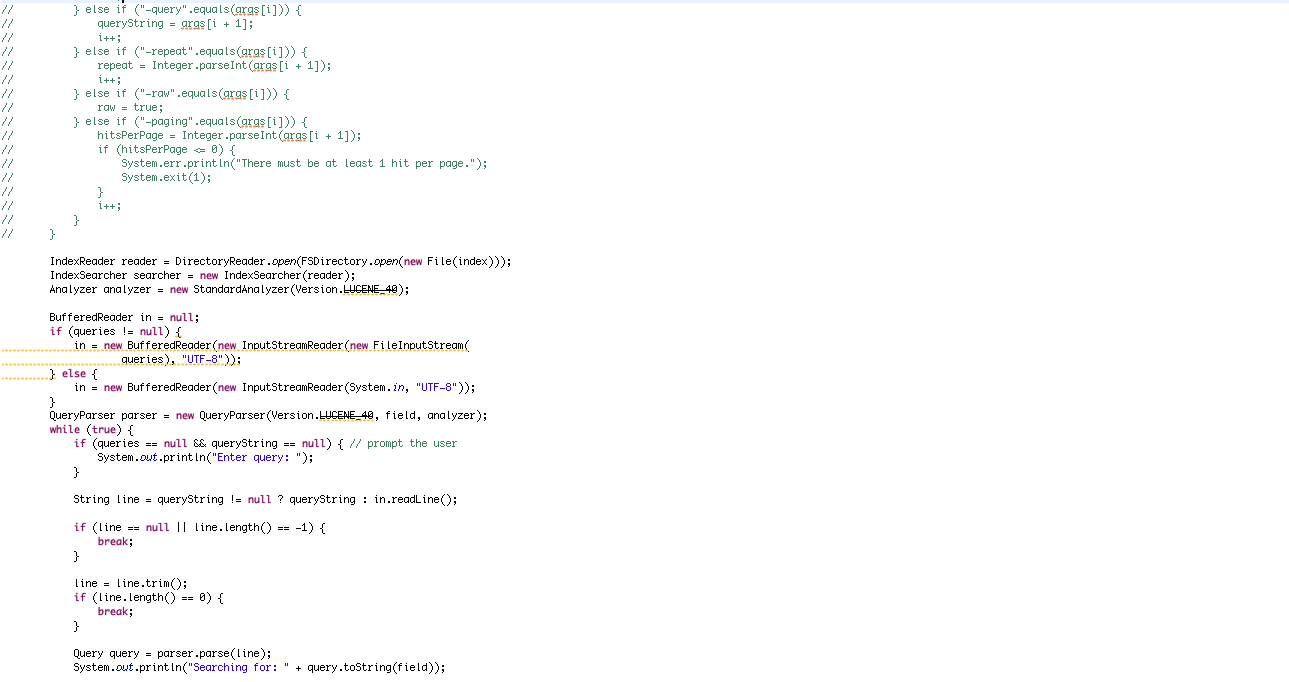
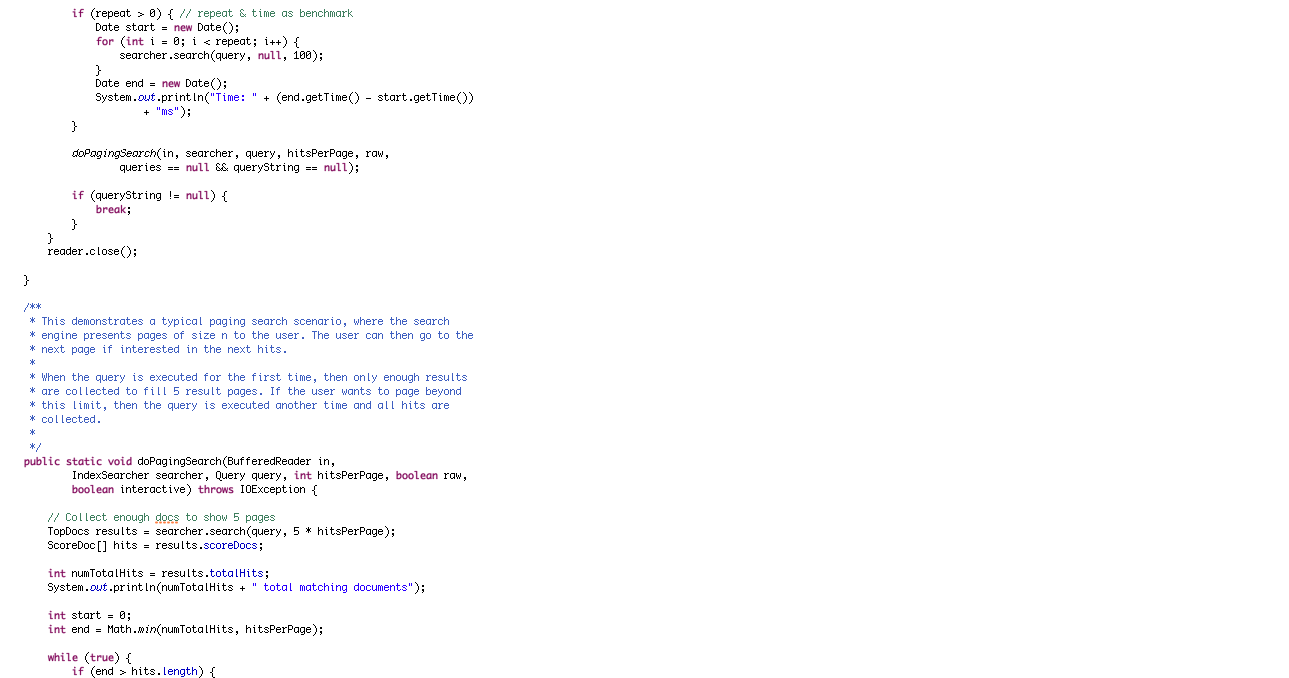

1.5 색인 관련 핵심 클래스
Indexer 클래스에서 본것 처럼 색인 기능을 구현 하려면 다음과 같은 클래스를 사용해야 한다.
IndexWriter, Directory, Analyzer, Document, Field
다섯가지 핵심 클래스가 색인 과정에 어떻게 관여하는지를 살펴 본다.
1.5.1 IndexWriter
IndexWriter 클래스는 색인 과정에서 가장 중심에 해당하는 클래스 이다. IndexWriter에서는 색인을 새로 생성하거나 기존 색인을 열고 문서를 추가하거나 삭제하거나 변경하는 기능을 담당한다. IndexWriter 클래스는 색인을 변경하는 기능을 가지고 있지만 색인된 내용을 검색하건 꺼내 볼수는 없다. 색일을 할 공간이 따로 필요하며, 색인을 저장하는 공간은 Directory로 표현된다.
1.5.2 Directory
Directory 클래스는 루씬의 색인을 저장하는 공간을 나타낸다. Directory 클래스 자체는 추상 클래스 이며 색인을 저장할 공간에 따라 Directory 클래스를 상속받아 필요한 메소드를 구현해야 한다.Indexer 예제 프로그램에서는 루씬 색인을 특정 디렉토리 안에 파일로 보관하는 FSDirectory 클래스를 사용했으며, IndexWriter 클래스를 생성할때 생성되는 메소드에 FSDirectory를 지정했다.
1.5.3 Analyzer
본문이나 제목등의 텍스트를 색인하기 전에 반드시 분석기를 거쳐 단어로 분리해야 한다. Analyzer 클래스는 Directory와 함께 IndexWriter 클래스의 생성 메소드에 지정하며, 지정된 텍스트를 색인할 단위 단어로 분리하고 필요없는 단어를 제거하는 등의 역할을 담당한다. 색인할 내용이 일반 텍스트가 아니라면 먼저 분석기를 통과하기 전에 텍스트로 변환하거나 텍스트를 추출해야 한다.
1.5.4 Doucment
Document 클래스는 개별 필드의 집합이다. 가상문서라고 생각할수 있는데 웹페이지나 이메일 메시지, 텍스트 파일, 단순한 텍스트 등을 검색 결과로 받아보려는 결과 단위를 뜻한다. 문서 내부의 필드는 문서의 실제 내요이나 메타 정보를 담고 있다.
1.5.5 Field
색인의 각문서는 모두 두개 이상의 각자 이름이 지정된 개별 필드로 구성되며, 각 필드는 Field라는 클래스로 표현된다. 모든 필드는 따라서 각자의 이름과 값이 들어있으며 여러가지 설정을 지정할수 있으며, 필드마다 지정된 설정에 따라 필드의 값을 색인한다.
1.6 검색 관련 핵심 클래스
루씬에서 제공하는 기본적인 검색 API는 색인 과정과 비슷하게 매우 간단하다.
IndexSearcher, Term, Query, TermQuery, TopDocs가 있다.
1.6.1 IndexSearcher
색인 과정을 담당하던 IndexWriter 클래스 처럼 검색을 담당하는 클래스 이고, 여러종류의 검색 메소드를 지원한다. IndexSearcher 클래스는 색인을 읽기 전용으로 열어 사용한다. 따라서 생성 메소드에 이미 색인이 들엉 ㅣㅆ는 Directory 인스턴스를지정해야 하며, 여러 종류의 검색 관련 메소드를 지원한다.
일반적인 사용방법은 다음과 같다.
Directory dir = FSDirectory.open(new File(“/tmp/index”));
IndexSearcher searcher = new IndexSearcher(dir);
Query q = new TermQuery(new Term(“contents”, “lucene”));
TopDocs hits = search.search(q,10);
Searcher.close();
1.6.2 Term
Term은 검색 과정을 구성하는 가장 기본적인 단위 이다. Field 클래스 처럼 Term 클래스도 필드 이름과 해당 필드에 속한 특정 단어의 쌍으로 이뤄진다. 위의 예제중
Query q = new TermQuery(new Term(“contents”, “lucene”));
TopDocs hits = search.search(q,10);
이부분에 해당하며 contents라는 이름의 필드에서 lucene이란 단어를 포함하는 문서중 연관도 기준 내림차순으로 상위 10개의 문서를 찾아오는 기능을 구현하는 코드이다.
1.6.3 Query
가장 최소한의 공통 부분만 갖고 있는 최상위 질의 클래스다. Query 클래스에서는 여러가지 도우미 메소드가 구현되어있다.
1.6.4 TermQuery
루씬에서 지원하는 질의중 가장 기본적인 기근을 가지고 있다. 특정 필드에 원하는 단어가 들어있는 문서를 찾아낸다.
1.6.5 TopDocs
단순히 검색 결과중 최상위N개의 문서에 대한 링크를 담고 있는 결과 클래스다. 최상위 N 개의 결과 마다 각 문서의 정수형 docID 값과 float 자료형의 점수를 담고 있다.